(substitution). Dans les chiffrements de remplacement, les lettres sont remplacées par d'autres lettres du même alphabet ; lors du codage, les lettres sont remplacées par quelque chose de complètement différent - images, symboles d'autres alphabets, séquences de caractères différents, etc. Une table de correspondance sans ambiguïté entre l'alphabet du texte source et les symboles de code est compilée, et conformément à cette table, un codage un à un se produit. Pour décoder, vous devez connaître la table de codes.
Il existe un grand nombre de codes utilisés dans différents domaines de la vie humaine. Les codes bien connus sont principalement utilisés pour faciliter le transfert d'informations d'une manière ou d'une autre. Si la table de codes n'est connue que de l'émetteur et du récepteur, alors un chiffre plutôt primitif est obtenu, qui se prête facilement à une analyse de fréquence. Mais si une personne est loin de la théorie du codage et n'est pas familière avec l'analyse fréquentielle du texte, alors il lui est plutôt problématique de deviner de tels chiffrements.
A1Z26
Le chiffre le plus simple. Il s'appelle A1Z26 ou dans la version russe A1Я33. Les lettres de l'alphabet sont remplacées par leurs nombres ordinaux.
"NoZDR" peut être chiffré comme 14-15-26-4-18 ou 1415260418.
Morse

Des lettres, des chiffres et certains signes sont associés à un ensemble de points et de tirets, qui peuvent être transmis par la radio, le son, les coups, le télégraphe lumineux et les drapeaux de signalisation. Comme les marins ont un drapeau correspondant associé à chaque lettre, il est possible de transmettre un message avec des drapeaux.
Braille
Le braille est un système de lecture tactile pour les aveugles, composé de caractères à six points appelés cellules. La cellule mesure trois points de haut et deux points de large.
Différents caractères braille sont formés en plaçant des points à différentes positions dans une cellule.
Pour plus de commodité, les points sont décrits lors de la lecture comme suit : 1, 2, 3 de gauche de haut en bas et 4, 5, 6 de droite de haut en bas.

Lors de la rédaction du texte, les règles suivantes sont respectées :
une cellule est sautée entre les mots (espace) ;
aucune cellule n'est ignorée après la virgule et le point-virgule ;
un tiret est écrit avec le mot précédent;
le numéro est précédé d'un signe numérique.

Pages de codes
Dans les quêtes et les énigmes informatiques, vous pouvez encoder des lettres en fonction de leurs codes dans diverses pages de codes - des tableaux utilisés sur les ordinateurs. Pour les textes cyrilliques, il est préférable d'utiliser les encodages les plus courants : Windows-1251, KOI8, CP866, MacCyrillic. Bien que pour un cryptage complexe, vous pouvez choisir quelque chose de plus exotique.
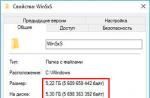
Vous pouvez encoder avec des nombres hexadécimaux ou les convertir en nombres décimaux. Par exemple, la lettre E dans KOI8-R a le code B3 (179), dans CP866 c'est F0 (240) et dans Windows-1251 c'est A8 (168). Et vous pouvez rechercher des lettres dans les tableaux de droite pour une correspondance dans ceux de gauche, puis le texte s'avérera être tapé en "krakozyabrami" comme èαᬫº∩íαδ (866 → 437) ou Êðàêîçÿáðû (1251 → latin-1).
Et vous pouvez remplacer la moitié supérieure des caractères par la moitié inférieure dans un tableau. Ensuite pour Windows-1251 au lieu de "krakozyabra" vous obtenez "jp" jng ap ("au lieu de" HELICOPTER "-" BEPRNK (R ". Un tel décalage dans la page de code est une perte classique du bit le plus significatif en cas de pannes sur les serveurs de messagerie. peut être encodé avec un décalage inverse vers le bas de 128 caractères, et cet encodage sera une variante du chiffre - ROT128, non seulement pour l'alphabet habituel, mais pour la page de code sélectionnée.
L'heure exacte de l'origine du chiffre est inconnue, mais certains des enregistrements trouvés de ce système datent du 18ème siècle. Des variantes de ce chiffre ont été utilisées par l'Ordre rosicrucien et les francs-maçons. Ces derniers l'utilisaient assez souvent dans leurs documents secrets et leur correspondance, c'est pourquoi le chiffre a commencé à être appelé le chiffre des francs-maçons. Même sur les pierres tombales des maçons, vous pouvez voir les inscriptions utilisant ce chiffre. Un système de cryptage similaire a été utilisé pendant la guerre de Sécession par l'armée de George Washington, ainsi que par les prisonniers des prisons fédérales des confédérations américaines.
Vous trouverez ci-dessous deux options (bleu et rouge) pour remplir la grille de ces chiffrements. Les lettres sont disposées par paires, la deuxième lettre de la paire est dessinée avec un symbole en pointillé :

Chiffres du droit d'auteur
Les chiffrements, où un caractère de l'alphabet (lettre, chiffre, signe de ponctuation) correspond à un (rarement plus) caractère graphique, de nombreux ont été inventés. La plupart d'entre eux sont conçus pour être utilisés dans des films de science-fiction, des dessins animés et des jeux informatiques. Voici quelques-uns d'entre eux :
Les hommes qui dansent
L'un des chiffrements de substitution de copyright les plus connus est "". Il a été inventé et décrit par l'écrivain anglais Arthur Conan Doyle dans l'un de ses ouvrages sur Sherlock Holmes. Les lettres de l'alphabet sont remplacées par des caractères qui ressemblent à des hommes dans diverses poses. Dans le livre, les petits hommes n'ont pas été inventés pour toutes les lettres de l'alphabet, alors les fans ont modifié et retravaillé les symboles de manière créative, et le code suivant a été obtenu :

L'alphabet de Thomas More
Mais un tel alphabet a été décrit dans son traité « Utopie » par Thomas More en 1516 :

Chiffres de la série animée "Gravity Falls"
Bill Shifra

Stanford Pines (écrivain de journal intime)

Alphabet Jedi de Star Wars

Alphabet extraterrestre de "Futurama"

L'alphabet krypton de Superman

Alphabets bioniques


Sémantique(fr. sémantique du grec ancien. σημαντικός - désignant) - la science de la compréhension de certains signes, séquences de symboles et autres conventions. Cette science est utilisée dans de nombreux domaines : linguistique, proxémique, pragmatique, étymologie, etc. Je ne sais pas ce que signifient ces mots et ce que font toutes ces sciences. Et ce n'est pas grave, je m'intéresse à la question de l'application de la sémantique dans la mise en page des sites.
La note
Je n'aborderai pas ici le terme Web sémantique. À première vue, il peut sembler que les thèmes du Web sémantique et du code HTML sémantique sont presque la même chose. Mais en fait, le Web sémantique est un concept plutôt philosophique et n'a pas grand-chose en commun avec la réalité actuelle.
Disposition sémantique - qu'est-ce que c'est ?
Dans la langue, chaque mot a un sens, un but précis. Quand vous dites "saucisse", vous voulez dire un produit alimentaire qui est de la viande hachée (généralement de la viande) dans une enveloppe oblongue. Bref, vous parlez de saucisse, pas de lait ou de pois verts.
HTML est aussi un langage, ses « mots », appelés balises, ont également une certaine signification logique et un certain but. Par conséquent, tout d'abord le code HTML sémantique est une mise en page avec l'utilisation correcte des balises HTML, en les utilisant aux fins prévues, telles qu'elles ont été conçues par les développeurs du langage HTML et des normes Web.
microformats.org est une communauté qui travaille pour donner vie aux idées idéalistes du Web sémantique en rapprochant le balisage des pages de ces idéaux sémantiques.
Pourquoi et qui a besoin d'une mise en page sémantique ?
Si sur mon site les informations sont affichées de la même manière que sur le design, pourquoi devriez-vous encore vous casser la tête et penser à une certaine sémantique ?! C'est du travail supplémentaire ! Qui en a besoin ?! Qui l'appréciera à part un autre maquettiste ?
J'ai souvent entendu de telles questions. Trouvons-le.
HTML sémantique pour les développeurs Web
Code sémantique pour les utilisateurs
Augmente la disponibilité des informations sur le site. Ceci est principalement important pour les agents alternatifs tels que:
- le code sémantique affecte directement la quantité de code HTML. Moins de code -> pages plus faciles -> chargement plus rapide, moins de RAM est nécessaire du côté utilisateur, moins de trafic, moins de taille de base de données. Le site devient plus rapide et moins cher.
- navigateurs vocaux pour lesquels les balises et leurs attributs sont importants afin de prononcer le contenu correctement et avec l'intonation nécessaire, ou inversement, pour ne pas trop prononcer.
- appareils mobiles qui ne supportent pas totalement CSS et s'appuient donc principalement sur du code HTML, l'affichant à l'écran en fonction des balises utilisées.
- périphériques d'impression même sans CSS supplémentaire, les informations s'imprimeront mieux (plus proches de la conception), et la création de la version parfaite pour l'impression se transformera en quelques manipulations CSS faciles.
- en outre, il existe des appareils et des plugins qui vous permettent de parcourir rapidement le document - par exemple, par en-têtes dans Opera.
HTML sémantique pour les machines
Les moteurs de recherche améliorent constamment leurs méthodes de recherche afin que les résultats incluent les informations qui cherche vraiment utilisateur. Le HTML sémantique facilite cela car se prête à une bien meilleure analyse - le code est plus propre, le code est logique (vous pouvez clairement voir où se trouvent les en-têtes, où se trouve la navigation, où se trouve le contenu).
Un bon contenu et une mise en page sémantique de haute qualité sont déjà une application sérieuse pour bonnes positions dans les résultats des moteurs de recherche.
La sémantique du code HTML est toujours un sujet brûlant. Certains développeurs essaient de toujours écrire du code sémantique. D'autres critiquent les adhérents dogmatiques. Et certains n'ont même aucune idée de ce que c'est et pourquoi c'est nécessaire. La sémantique est définie en HTML dans des balises, des classes, des identifiants et des attributs qui décrivent l'objectif, mais ne spécifient pas exactement le contenu qu'elles contiennent. C'est-à-dire que nous parlons de la séparation du contenu et de son format.
Commençons par un exemple évident.
Mauvaise sémantique du code
Bonne sémantique du code
Le texte de l'article, qui a été écrit par quelqu'un. Inco Gnito- son auteur.Le titre de l'article
Que vous pensiez que HTML5 est prêt à l'emploi ou non, très probablement en utilisant la balise Mais tout n'est pas aussi clairement représenté avec les balises HTML5. Jetons un coup d'œil à un ensemble de noms de classes et voyons s'ils répondent aux exigences sémantiques. Pas de code sémantique. C'est un exemple classique. Chaque atelier CSS pour grille modulaire utilise ce type de noms de classe pour définir les éléments de grille. Que ce soit "yui-b", "grid-4" ou "spanHalf", ces noms sont plus proches de la description du balisage que de la description du contenu. Cependant, leur utilisation dans la plupart des cas est inévitable lorsque l'on travaille avec des modèles de grilles modulaires. Code sémantique. Le pied de page a pris un sens durable dans la conception de sites Web. Il s'agit du pied de page de la page qui contient des éléments tels que la navigation répétée, les droits d'utilisation, les informations sur l'auteur, etc. Cette classe définit un groupe pour tous ces éléments sans leur description. Si vous êtes passé à HTML5, il est préférable d'utiliser l'élément Pas de code sémantique. Il définit précisément le contenu. Mais pourquoi le texte devrait-il être grand ? Pour se démarquer des autres textes plus petits ? "standOut" (sélection) est plus approprié dans ce cas. Vous pouvez décider de changer le style du texte de surbrillance, mais ne faites rien avec sa taille, auquel cas le nom de la classe peut vous embrouiller. Code sémantique. Dans ce cas, il s'agit de déterminer le niveau d'importance d'un élément de l'interface de l'application (par exemple, un paragraphe ou un bouton). Un élément de niveau supérieur peut avoir des couleurs vives et des tailles plus grandes, tandis que les éléments de niveau inférieur peuvent contenir plus de contenu. Mais il n'y a pas de définition exacte des styles dans ce cas, donc le code est sémantique. Cette situation est très similaire à l'utilisation de balises Code sémantique. Si seulement chaque nom de classe pouvait être si clairement défini ! Dans ce cas, nous avons une description d'une section dont le contenu est facile à décrire, tout comme "tweets", "pagination" ou "admin-nav". Pas de code sémantique. Dans ce cas, nous parlons de définir le style du premier paragraphe de la page. Cette technique est utilisée pour attirer l'attention des lecteurs sur le matériel. Mieux vaut utiliser le nom "intro", qui ne mentionne pas l'élément. Mieux encore, utilisez un sélecteur pour ces paragraphes, comme l'article p: first-of-type ou h1 + p. Pas de code sémantique. Il s'agit d'un nom de classe très générique qui est utilisé pour organiser le formatage des éléments. Mais il n'y a rien dedans pour décrire le contenu. Divers théoriciens de la sémantique recommandent d'utiliser un nom de classe comme « groupe » dans de tels cas. Il est probable qu'ils aient raison. Puisque cet élément sert sans aucun doute à regrouper plusieurs autres éléments, et le nom recommandé décrirait mieux sa fonction sans entrer dans les détails. Pas de code sémantique. Description trop détaillée du format du contenu. Il est préférable de choisir un nom différent qui décrit le contenu, plutôt que son format. Code sémantique. La classe décrit très bien l'état du contenu. Par exemple, le message de réussite peut avoir un style complètement différent du message d'erreur. Pas de code sémantique. Cet exemple essaie de définir le format du contenu, pas son objectif. "plain-jane" est très similaire à "normal" ou "regular". Idéalement, CSS devrait être écrit de telle sorte qu'il n'y ait pas besoin de noms de classe comme « regular » pour décrire le format du contenu. Pas de code sémantique. Ces types de classes sont couramment utilisés pour définir des éléments de site qui ne doivent pas être inclus dans une chaîne de liens. Dans ce cas, il est préférable d'utiliser quelque chose comme rel = nofollow pour les liens, mais pas une classe pour tout le contenu. Pas de code sémantique. Il s'agit d'une tentative de décrire le format du contenu, et non son objectif. Disons que vous avez deux articles sur votre site. Et vous voulez leur donner des styles différents. Les critiques de films auront un fond bleu et Hot News aura un fond rouge et une police plus grande. L'un des moyens de résoudre le problème est le suivant : Une autre façon est la suivante : Certes, si vous demandez à plusieurs développeurs quel code est le plus cohérent avec les exigences de la sémantique, la plupart pointeront vers la première option. Cela correspond parfaitement au matériel de ce tutoriel : une description de l'objet sans références de formatage. Et la deuxième option indique le format ("blueBg" est un nom de classe formé de deux mots anglais signifiant "fond bleu"). Si soudainement une décision est prise de changer la conception des critiques de films - par exemple, pour créer un fond vert, alors le nom de classe "blueBg" deviendra le cauchemar d'un développeur. Et le nom « movie-review » vous permettra de changer complètement les styles visuels tout en conservant un excellent niveau de prise en charge du code. Mais personne ne prétend que le premier exemple est meilleur dans tous les cas sans exception. Disons qu'une nuance particulière de bleu est utilisée à de nombreux endroits sur le site. Par exemple, il s'agit de l'arrière-plan de certains pieds de page et de certaines zones de la barre latérale. Vous pouvez utiliser le sélecteur suivant : Critique de film, pied de page> div : nième de type (2), aparté> div : nième de type (4) (arrière-plan : # c2fbff ;) Une solution efficace, puisque la couleur est déterminée à un seul endroit. Mais un tel code devient difficile à maintenir, car il possède un long sélecteur difficile à visualiser. Vous aurez également besoin d'autres sélecteurs pour définir des styles uniques, ce qui conduira à un code répétitif. Ou vous pouvez adopter une approche différente et les laisser séparés : Critique du film (arrière-plan : # c2fbff ; / * Définition de la couleur * /) pied de page> div : nth-of-type (2) (arrière-plan : # c2fbff; / * Et encore une chose * /) à part> div : nth-of - tapez (4) (fond : #c2fbff; / * Et encore une chose * /) Ce style permet de garder le fichier CSS plus organisé (différentes zones sont définies dans différentes sections). Mais la répétition des définitions a un prix. Pour les grands sites, la définition d'une même couleur peut aller jusqu'à plusieurs milliers de fois. Terrible! Une solution serait d'utiliser une classe comme "blueBg" pour définir la couleur une fois et l'insérer dans le code HTML lorsque vous souhaitez utiliser le design donné. Bien sûr, il est préférable de le nommer "mainBrandColor" ou "secondaryFont" pour se débarrasser de la description de la mise en forme. Vous pouvez sacrifier la sémantique de votre code au profit de la conservation des ressources. ,
,
, et ainsi de suite, mais à d'autres éléments d'interface.
Mais...