Salutations, lecteur de mon blog. Je n'ai pas écrit d'articles depuis longtemps. Beaucoup de changements de vie ... L'article d'aujourd'hui sera consacré à syslog, ou plutôt rsyslog, qui est activement implémenté à la place de l'ancien syslogd (alias sysklogd) dans les dernières distributions (par exemple, etc.). J'ai donné une description de base de la fonctionnalité dans l'article correspondant. Par conséquent, avant de lire ce qui suit, je vous conseille fortement de lire. Pour le moment, la tâche pour moi est collecter les journaux système syslog à partir de l'équipement réseau d'un montant de ~ 100 hôtes avec une augmentation ultérieure de leur nombre. Je vais essayer d'implémenter cette fonctionnalité dans cet article, après avoir précédemment décrit et. Le tout sera décrit sur la base de Debian 6, dans d'autres distributions, avec l'expérience, avec un minimum de mouvements de fichiers, je pense que ce ne sera pas non plus difficile à mettre en place. Alors, commençons...
Introduction à rsyslog
Comme je l'ai déjà dit, rsyslog est devenu le package par défaut sur la plupart des distributions Linux (probablement toutes). Rsyslog coïncide totalement protocole syslog, décrit dans, et contient également quelques fonctionnalités supplémentaires. Tels que le transport TCP, le filtrage et le tri des messages, le stockage des messages dans un SGBD, le cryptage et bien d'autres. Dans l'article, je vais essayer de considérer la description, la description contrôle du démon rsyslogd et .
Installation de rsyslogd
L'installation de rsyslog (s'il n'est pas installé par défaut pour une raison quelconque) se résume à une seule commande :
Aptitude installer rsyslog # chapeau rouge possible yum installer rsyslog
Directives de configuration
Les directives de configuration sont parfois appelées directives globales, elles spécifient paramètres généraux du démon rsyslogd... La directive a le format $ Paramètre de directive
############################ #### DIRECTIVES GLOBALES #### ############## # ############## # Spécifie l'utilisation du format d'horodatage classique (Mes DD HH : MM : SS). # Pour activer les horodatages au format Unix, vous devez commenter la ligne. $ ActionFileDefaultTemplate RSYSLOG_TraditionalFileFormat # # Définit la valeur par défaut pour les fichiers journaux. $ FileOwner root $ FileGroup adm $ FileCreateMode 0640 $ DirCreateMode 0755 $ Umask 0022 # # Définit l'emplacement des fichiers spool et statiques (pour stocker des fichiers tels que les files d'attente de messages) $ WorkDirectory / var / spool / rsyslog # # Inclut toutes les configurations dans *. conf du répertoire /etc/rsyslog.d/ $ IncludeConfig /etc/rsyslog.d/*.confLa liste la plus complète des directives mondiales est disponible.
Modèles Rsyslog
Très important et clé une fonctionnalité de rsyslogd est la possibilité d'utiliser des modèles. Le modèle vous permet de : 1. définissez le format des informations de sortie, 2. utilisez les noms dynamiques des fichiers journaux en fonction d'une règle. Réellement, tous les messages de sortie vers rsyslogd sont basés sur des modèles. Ici, la question correspondante peut se poser - comment la sortie est-elle formée si vous ne spécifiez aucun modèle dans rsyslog.conf(après tout, aucun modèle n'est spécifié par défaut) ? C'est simple. Il existe quelques modèles (tirés des modèles compatibles et écrits statiquement dans les sources rsyslog). La confirmation de ce cas peut être trouvée dans le fichier source syslogd.c en recherchant "template_" (trébucher sur / * modèles standard codés en dur (utilisés par défaut) * /). Les modèles doivent être spécifiés avant utiliser dans les règles.
Syntaxe du modèle
En général, la structure d'un modèle peut être représentée dans la syntaxe suivante :
$ modèle nom_modèle, modèle_description[, options (facultatif)]Jetons un coup d'œil à chaque point. $ modèle- indique que la description du modèle suivra. nom_modèle- une valeur arbitraire qui décrit clairement quel type de modèle est et à quoi sert (le nom sera utilisé pour faire référence au modèle). options- peut prendre la valeur sql et sqlstd, cela vous oblige à formater le résultat final de l'exécution du modèle sous une forme adaptée respectivement à MySQL ou SQL standard (en fait, il remplace certains caractères spéciaux dans le message syslog dans un format pris en charge par le serveur SQL). Les options s'appliquent uniquement aux modèles pour la sortie SQL.
modèle_description est entre guillemets. Dans les modèles entre guillemets, tout texte est pris littéralement (tel quel), à l'exception du texte qui est entouré de signes de pourcentage ( %texte%). Un tel texte est une variable et vous permet d'"accéder" au contenu interne du message entrant et d'obtenir ainsi toutes sortes de fonctionnalités de modification amusantes). En outre, entre guillemets peuvent être utilisés ainsi. séquences d'échappement sous la forme d'une barre oblique inverse et d'un caractère après la ligne (par exemple, \ n - newline, \ 7 - ...).
Utilisation de variables dans les modèles rsyslog
Passons en revue la structure des valeurs spécifiées en% pour cent%.
% nom_propre [ : début de ligne : fin de ligne : options [ : nom de champ]]%nom propre(il est nom de la propriété, il est Nom de variable) - définit le nom de la propriété (dans ce contexte, une propriété peut être considérée comme une propriété \ champ d'un message syslog passant par le démon), voici quelques-unes des plus utilisées avec propriétés rsyslog:
- message- Corps du message
- nom d'hôte- nom d'hôte \ ip du message
- de l'hôte- le nom de l'hébergeur d'où provient le message
- dehost-ip- adresse de l'hôte d'où proviennent les messages (127.0.0.1 pour les messages locaux)
- syslogtag- le nom et le numéro du processus ("rsyslogd:") qui a émis le message (extrait du message)
- nom du programme- le nom du processus qui a émis le message (extrait du message)
- pri- source et priorité, sous forme de nombre
- pri-texte- source décodée et priorité ( établissement.priorité par exemple syslog.emer)
- syslogfacilité- source uniquement sous forme de numéro
- syslogfacility-text- source décodée uniquement ("local0")
- syslogseverity- uniquement la priorité en tant que numéro
- syslogseverity-text- seul niveau décodé ("debug")
- généré par le temps- temps d'acquisition (haute résolution)
- heure rapportée- heure extraite du message
- nom d'entrée- le nom du module d'entrée
- $ heure, $ minute- heure actuelle
- $ monnom d'hôte- traitement du nom d'hôte
Comme vous pouvez le voir, certaines propriétés commencent par un signe dollar - elles sont considérées comme locales / système.
Plus loin - options... Les options vous permettent de modifier une variable dans la plage allant d'un signe de pourcentage à un signe de pourcentage. Vous pouvez utiliser plusieurs options en même temps, séparées par des virgules. Si vous spécifiez plusieurs caractères contradictoires (par exemple, majuscule, minuscule), alors le dernier spécifié (minuscule) sera appliqué. Voici quelques options :
- majuscule- conversion en majuscule
- minuscule- convertir en minuscules
- date-mysql- convertir au format de date MySQL
- espace-cc- remplacer les caractères de contrôle par des espaces
- déposer-cc- supprimer les caractères de contrôle
nom de domaine- ce champ est disponible depuis la version 6.3.9+ et a un caractère bien particulier. Tu peux l'oublier...
Comme vous pouvez le voir dans le modèle de variable ci-dessus, les valeurs des accolades sont facultatives, c'est-à-dire que vous pouvez simplement spécifier, par exemple% nom d'hôte%. Cependant, si des options doivent être utilisées, les champs vides précédents doivent également être spécifiés, par exemple% nom d'hôte ::: minuscule%. Il manque des champs entre les deux points start_line et end_line... En même temps, pour une raison quelconque, fieldname n'est pas spécifié comme vide.
Modèles qui sont codés en dur dans rsyslog (mais qui peuvent être modifiés avec la directive $ ActionFileDefaultTemplate):
RSYSLOG_SyslogProtocol23Format- le format défini dans le projet de norme IETF ietf-syslog-protocol-23 correspond au modèle :
"<%PRI%>1% TIMESTAMP ::: date-rfc3339%% HOSTNAME%% APP-NAME%% PROCID%% MSGID%% STRUCTURED-DATA%% msg% \ n \ "
RSYSLOG_FileFormat- le format de log traditionnel, avec l'ajout de fractions de seconde et d'une zone, suit le schéma :
"% TIMESTAMP ::: date-rfc3339%% HOSTNAME%% syslogtag %% msg ::: sp-if-no-1st-sp %% msg ::: drop-last-lf% \ n \"
RSYSLOG_TraditionalFileFormat- le format de journal traditionnel pour l'écriture dans un fichier suit le modèle suivant :
"% TIMESTAMP%% HOSTNAME%% syslogtag %% msg ::: sp-if-no-1st-sp %% msg ::: drop-last-lf% \ n \"
RSYSLOG_ForwardFormat- le format de log traditionnel pour la transmission avec l'ajout de fractions de seconde et d'une zone, suit le schéma :
"<%PRI%>% TIMESTAMP ::: date-rfc3339%% HOSTNAME%% syslogtag: 1: 32 %% msg ::: sp-if-no-1st-sp %% msg% \ "
RSYSLOG_TraditionalForwardFormat- format de journal traditionnel pour le transfert vers un serveur distant
"<%PRI%>% TIMESTAMP%% HOSTNAME%% syslogtag : 1 : 32 %% msg ::: sp-if-no-1st-sp %% msg% \ "
Règles de tri Rsyslog (ligne de règle)
Chaque ligne de règles de tri a un format classique, comme dans un syslog normal. Pour comprendre quoi et comment, vous devez lire l'article. En bref : la règle consiste à sélecteur et Actions séparés par un espace ou une tabulation. Sélecteur se compose à son tour la source et priorité... Chaque message est vérifié par rapport au sélecteur de chaque règle de manière séquentielle, si le sélecteur de message et la règle correspondent, alors l'action spécifiée est exécutée. Dans le même temps, après le premier match, le traitement ne s'arrête pas. Devant action, le message est converti conformément au modèle (le modèle par défaut spécifié dans la directive correspondante (remplaçant le modèle par défaut), le modèle spécifié dans cette action est l'un des trois).
Vers les fonctionnalités standard sélecteurs syslog quelques fonctionnalités supplémentaires ont été ajoutées (je vous rappelle que le sélecteur classique est source.priorité il est établissement.priorité). Dans rsyslog, les valeurs peuvent être utilisées comme sélecteurs. Dans rsyslog, l'application de variables dans un sélecteur est appelée Filtres... Ci-dessus dans l'article, ainsi que dans la description de l'approche classique du filtrage basé sur source.priorité(soi-disant sélecteurs "traditionnels" de gravité et d'installation). En plus du filtrage traditionnel, il existe les éléments suivants types de filtration: Filtres basés sur RainerScript(filtrage basé sur le langage RainerScript - en fait un if - then - else normal), filtres basés sur les propriétés(filtrage basé sur les propriétés du message (comme dans)). Regardons les deux :
Filtres basés sur RainerScript
Comme je l'ai dit, RainerScript est un langage classique basé sur sinon. Dans rsyslog, RainerScript prend en charge l'imbrication de conditions, les opérations arithmétiques, booléennes et de chaîne. En général, la syntaxe est la suivante :
si condition alors action_block autre bloc d'actionRespectivement, si donc sont des opérateurs obligatoires qui définissent la construction d'une condition, autre- De nécessité. bloc_action - peut contenir une action (), ou un bloc de conditions imbriqué. Si un bloc de conditions contient plusieurs actions, il est alors mis entre parenthèses. état- contient une condition de sélection des messages pour un action_block. Dans une condition, vous pouvez utiliser :
- expressions logiques(et, ou, non), ainsi que de regrouper ces expressions sous la forme : pas condition0 et (condition1 et condition2).
- variables (propriétés)- les variables sont spécifiées sous la forme $ variable_name (par exemple, $ hostname ou $ msg)
- opérations de comparaison(== - égal,! = - pas égal,> - plus,< - меньше, <= - меньше или равно, >= - supérieur ou égal, (!) contient - (non) contient, (!) commence par - (ne) commence par)
- commentaires / * commentaires * /(point discutable... faut-il s'échapper comme dans bash ???)
Cisco
as53xx231 # conf t Entrez les commandes de configuration, une par ligne. Terminez par CNTL/Z. as53xx231 (config) #logging 10.0.0.1 as53xx231 (config) #exitVMware ESXi
Pour un ancien hyperviseur :
Ajoutez ce qui suit à /etc/syslog.conf :
*. * @ 10.0.0.1 # syslog doit être activé dans le firewall et enregistré : esxcfg-firewall -o 514, udp, out, syslog esxcfg-firewall -l # restart syslog service syslog restart
Dans les dernières versions de l'hyperviseur, tout se fait via le client guish. Dans les paramètres de l'hyperviseur Advansed -> Syslog -> remote, spécifiez l'adresse du serveur rsyslog.
Stockage de rsyslog dans le SGBD MySQL
Dans Debian, la configuration du stockage dans une base de données est très simple (presque comme chez un fournisseur)). En général, il suffit d'installer le paquet rsyslog-mysql. En même temps, le programme d'installation place le module ommysql.so dans le répertoire /usr/lib/rsysloul/sang/ et lance l'assistant d'installation, qui demande le mot de passe administrateur MySQL, crée un utilisateur séparé et demande un mot de passe pour celui-ci . Crée la base de données correspondante à partir du script /usr/share/dbconfig-common/data/rsyslog-mysql/install/mysql. Placez les paramètres résultants dans /etc/rsyslog.d/mysql.conf. La config est obtenue à partir de 2 lignes :
# connexion au module : $ ModLoad ommysql # envoie tous les messages à MySQL (rappelez-vous ci-dessus Actions) *. * : ommysql : server_address, database_name, username, password
Interface Web Rsyslog
En tant qu'interface Web, nous allons configurer le Loganalizer depuis adiscon. L'installation de l'interface Web est assez simple. Elle consiste à télécharger l'archive, la décompresser dans le répertoire du serveur web et lancer l'assistant de configuration graphique. Donc, à partir d'ici (http://loganalyzer.adiscon.com/downloads) téléchargez l'archive avec les fichiers (Par exemple : http://download.adiscon.com/loganalyzer/loganalyzer-3.5.6.tar.gz). Avant la configuration, bien entendu, le serveur Web et le module php5 doivent être installés (aptitude install apache2 libapache2-mod-php5). Et oui, aussi php5-gd pour afficher les rapports.
~ # # Téléchargez l'archive : ~ # wget http://download.adiscon.com/loganalyzer/loganalyzer-3.5.6.tar.gz ~ # # décompressez l'archive : ~ # tar xf loganalyzer-3.5.6.tar. gz
Le répertoire loganalyzer-3.5.6 apparaît dans le répertoire courant et contient quelques informations à lire :
~ # ls -l total 12 drwxr-xr-x 3 racine racine 4096 20 sept. 22:51. drwx ------ 13 racine racine 4096 20 sept. 23:01 .. drwxrwxr-x 5 racine racine 4096 10 sept 17:26 loganalyzer-3.5.6 ~ # ls -l loganalyzer-3.5.6 / total 112 -rw -rw-r-- 1 racine racine 41186 10 sept. 17:26 ChangeLog drwxrwxr-x 2 racine racine 4096 20 sept. 23:01 contrib -rw-rw-r-- 1 racine racine 35497 10 sept. 17:26 COPIE drwxrwxr-x 2 root root 4096 Sep 10 17:34 doc -rw-rw-r-- 1 root root 8449 Sep 10 17:26 INSTALL drwxrwxr-x 14 root root 4096 Sep 10 17:34 src ~ # # à partir du répertoire src dont nous avons besoin pour copier du contenu dans /var/www/loganalyzer : ~ # mkdir / var / www / loganalyzer ~ # cp -r loganalyzer-3.5.6 / src / * / var / www / loganalyzer ~ # # ensuite, vous devez créer un fichier de configuration vide ~ # # qui sera rempli automatiquement - par l'installateur ~ # touch /var/www/loganalyzer/config.php ~ # # définir les autorisations d'écriture (après l'installation, ces autorisations peuvent être supprimées) ~ # chmod 666 / var/www/loganalyzer/config.php
Cliquez ici
Nous voyons pourquoi nous avons donné les droits 666, cliquez sur Suivant
Ici, nous sélectionnons les paramètres souhaités. Le paramètre Activer la base de données utilisateur requiert une attention particulière. Si vous le sélectionnez, une base de données distincte sera créée pour stocker les paramètres de l'interface Web. En outre, la possibilité de créer des utilisateurs et des groupes sera disponible. Cliquez sur Suivant.
Il y a un petit ajout - le serveur Web n'a pas accès aux fichiers réguliers dans le répertoire / var / log /. Par conséquent, le journal peut ne pas s'afficher. Pour résoudre ce problème, vous devez ajouter l'utilisateur www-data au groupe adm :
~ # usermod -G adm www-data
En plus de Loganalyzer, il y a aussi Logzilla, qui a la même fonctionnalité. Cela vaut également la peine d'essayer de l'installer, si vous le souhaitez.
Quelques trucs et astuces pour rsyslog
Parfois, lorsque rsyslog est un service réseau pour collecter des journaux distants, le stockage des messages par nom d'hôte est gênant ou improductif, ou autre chose. Pour désactiver la résolution des adresses IP dans les noms d'hôtes, ajoutez le paramètre -x :
~ # cat / etc / default / rsyslog RSYSLOGD_OPTIONS = "- c5 -x"
Afin de permettre le passage des paquets udp, vous devez utiliser la commande :
~ # iptables -A INPUT -p udp -s src_subnet --dport 514 -i interface -j ACCEPT
Quelques exemples de règles avec commentaires :
# si vous créez un sélecteur comme celui-ci : si $ fromhost-ip commence par "10.0.1." alors / quelque chose # vous devez faire attention au dernier point de l'adresse, # sinon la règle inclura les adresses du sous-réseau 10.0.111.0, 10.0.12.0 et autres
Pour un serveur centralisé de collecte des journaux des périphériques réseau, vous pouvez définir la fonction sur les périphériques réseau sur n'importe quelle valeur de local0-local7. Cela vous permettra de trier facilement les messages, par exemple :
# cisco: net-device-cisco # conf t Entrez les commandes de configuration, une par ligne. Terminez par CNTL/Z.<...>net-device-cisco (config) #logging facility local2<...># rsyslog-server local2. * /var/log/remote-cisco.log & ~
Ainsi, il est possible de filtrer facilement les messages locaux des messages distants.
Voici une configuration qui vous permet d'envoyer des notifications d'événements de messagerie (!!! le serveur de messagerie doit accepter les messages sans authentification) :
$ ModLoad ommail $ ActionMailSMTPServer smtp_address $ ActionMailSMTPPort 25 $ ActionMailFrom sender @ address $ ActionMailTo destinataire @ address $ template mail_subject, "On host% hostname%, Error-level by serverity" $ template mail_body, "Facility.Serverity:% syslogfacility%.% syslogpriority% at% timegenerated% on host:% HOSTNAME% \ r \ n% msg% "$ ActionMailSubject mail_subject # intervalle de temps (pause entre les lettres) $ ActionExecOnlyOnceEveryInterval 10 # filtre et action sinon ($ msg contient" quelque chose "\ ou $ msg contient "quelque chose d'autre" \ ou $ msg contient "peut-être quelque chose d'autre") \ et ($ syslogseverity-text == "err" \ ou $ syslogseverity-text == "crit" \ ou $ syslogseverity-text == " alert " \ ou $ syslogseverity-text == "emerg") \ alors : ommail:; mail_body
Trableshuting
Pour diagnostiquer le travail de syslog, ça aide beaucoup, un exemple de commande de monitoring :
~ # tcpdump -vvv -nn -i interface udp port 514
Et, bien sûr, /var/log/syslog lui-même.
Cette section fournit des recommandations pour travailler avec des programmes de collecte de journaux. Ces informations sont requises par le service d'assistance technique pour diagnostiquer avec précision le problème sur le lieu de travail de l'utilisateur. Les instructions pour les applications sont disponibles ci-dessous.
Collecte des journaux https à l'aide de FiddlerCap
Installation de FiddlerCap
Vous devez télécharger et exécuter l'application.
Dans la fenêtre qui s'ouvre, cliquez sur le bouton "Installer". La ligne Dossier de destination indiquera le chemin d'accès au dossier où FiddlerCap sera installé. Par défaut, le Bureau y est spécifié.
Attendez la fin de l'installation et cliquez sur le bouton "Fermer".

Collecte de logs avec FiddlerCap
Recherchez le dossier FiddlerCap dans le répertoire qui a été sélectionné lors de la phase d'installation. Par défaut, FiddlerCap est installé sur le bureau. Exécutez le fichier "FiddlerCap.exe" dans le dossier FiddlerCap.

Dans l'élément "Paramètres de capture", cochez trois cases :
- enregistrer des données binaires,
- décrypter le trafic HTTPS,
- stocker des cookies et des formulaires POST.

Si un avertissement concernant l'installation du certificat apparaît, cliquez sur le bouton "Oui" qu'il contient. Si nécessaire, vous serez invité à supprimer le certificat lors de l'enregistrement des journaux.

Fermez tous les navigateurs ouverts sur l'ordinateur. Cliquez sur le bouton "Démarrer la capture". Ouvrez le programme, lorsque vous travaillez avec lequel une erreur apparaît (par exemple, Contour.Extern), et reproduire l'erreur.

Une fois l'erreur reproduite, vous devez cliquer sur le bouton Arrêter la capture dans la fenêtre FiddlerCap. L'enregistrement se terminera.


Sélectionnez un dossier à enregistrer.

Le fichier journal sera enregistré dans le dossier sélectionné.

Lors de l'enregistrement des journaux, une fenêtre apparaîtra demandant de supprimer le certificat du magasin racine. À la discrétion de l'utilisateur, vous pouvez choisir n'importe quelle option.

Enregistrement du trafic réseau dans Internet Explorer
Pour enregistrer le trafic réseau dans Internet Explorer, vous devez ouvrir la page requise dans Internet Explorer. Dans Internet Explorer, accédez à Outils> Outils de développement F12 F12.
Si le menu "Service" ne s'affiche pas, appuyez sur la touche "Alt" du clavier.


Allez dans l'onglet Réseau> Ctrl + 4. Activer la collecte du trafic réseau : dans Internet Explorer 9, cliquez sur "Démarrer la collecte". Dans Internet Explorer 11, cliquez sur le bouton avec un triangle vert.

Reproduisez l'erreur (par exemple, actualisez la page ou suivez le lien requis). Enregistrez le journal collecté en cliquant sur l'image de la disquette.

V Sélectionnez le dossier à enregistrer, entrez le nom du fichier en appuyant surêtre "Enregistrer". Le fichier sera créé au format xml. La création du journal est terminée.

Enregistrement du trafic réseau dans Mozilla Firefox
Pour enregistrer le trafic réseau dans Mozilla Firefox, vous devez ouvrir la page requise dans Mozilla Firefox. Dans IMozilla Firefox, allez dans Outils> Développement> Outils de développement (Ctrl + Maj + I)ou appuyez sur la touche du clavier F12.
Allez dans l'onglet "Réseau" et rafraîchissez la page en cliquant sur touche du clavier F5... Reproduisez le bogue.

Sélectionnez n'importe quelle entrée dans le journal - faites un clic droit dessus et cliquez sur "Enregistrer tout en tant que HAR".

Enregistrement du trafic réseau dans Google Chrome
Pour enregistrer le trafic réseau dans Google Chrome, vous devez ouvrir la page requise dans Google Chrome. Dans Google Chrome, allez dans Outils> Plus d'outils> Outils de développement (Ctrl + Maj + I)ou appuyez sur la touche du clavier F12.
Passez à la section Réseau et rafraîchissez la page en appuyant sur la touche F5 de votre clavier... Reproduisez le bogue.

Si l'enregistrement ne démarre pas automatiquement, cliquez sur le bouton « Enregistrer le journal du réseau ».

Sélectionnez n'importe quelle entrée dans le journal, faites un clic droit dessus et cliquez sur "Enregistrer en tant que HAR avec contenu".
Sélectionnez un dossier à enregistrer, entrez un nom de fichier, cliquez sur enregistrer. Le fichier sera enregistré au format har.
Installation
Il faut sauter démarrer et exécuter l'application . L'offre de démarrer l'installation doit recevoir une réponse affirmative en cliquant sur le bouton "Oui".

Dans la fenêtre qui s'ouvre, cliquez sur le bouton "Suivant".

Dans la fenêtre suivante, vous devez sélectionner le bouton "J'accepte les termes du contrat de licence" et cliquer sur le bouton "Suivant".

Sélectionnez le type d'installation « Typique ».

Cochez la case "Créer un raccourci pour Microsoft Network Monitor sur le bureau" et cliquez sur le bouton "Installer".

Cliquez sur le bouton "Terminer" pour terminer l'installation.

Une fois l'installation terminée, vous devez attendre la fin de la configuration automatique du composant Microsoft Network Monitor 3.4 Parsers.

Commencer à se connecter
Fermez les logiciels inutilisés (cela est nécessaire pour exclure l'enregistrement de l'activité des produits tiers dans le journal). Lancez le programme en utilisant un raccourci sur le bureau.

Dans la fenêtre principale du programme, sélectionnez le menu "Fichier"> "Nouveau"> "Capturer".

Cliquez sur le bouton "Démarrer", puis fermez le programme et reproduisez l'erreur.

Pour reproduire l'erreur, cliquez sur le bouton "Stop".

V Sélectionnez le menu "Fichier">
"Enregistrer sous", spécifiez le répertoire de sauvegarde et le nom du fichier et cliquez sur le bouton "Enregistrer".La création du journal est terminée.

Moniteur de processus
Pour démarrer la journalisation à l'aide du programme Process Monitor, vous devez effectuer les étapes suivantes :
Fermez les logiciels inutilisés (cela est nécessaire pour exclure l'enregistrement de l'activité des produits tiers dans le journal), saut démarrer et exécuter l'application .
Après avoir démarré le programme, choisissez Fichier> Capturer les événements. L'enregistrement sera arrêté. Sélectionnez le menu "Edition"> "Effacer l'affichage". Le journal enregistré automatiquement sera supprimé. Le programme est prêt à partir.
Choisissez Fichier> Capturer les événements. L'enregistrement commencera. Réduisez l'application et reproduisez l'erreur.
Restaurez l'application et choisissez Fichier> Capturer les événements. L'enregistrement sera arrêté. Sélectionnez le menu "Fichier"> "Enregistrer". Activez le bouton radio "Tous les événements".

Cliquez sur le bouton avec trois points à droite du champ "Chemin", spécifiez le dossier de sauvegarde et le nom du fichier (il est recommandé de le laisser par défaut) et cliquez sur le bouton "Enregistrer".

Dans la fenêtre des paramètres d'enregistrement du fichier, cliquez sur le bouton "Enregistrer". La création du journal est terminée.
J'ai une faiblesse - j'aime les différents systèmes de surveillance. C'est-à-dire qu'une situation idéale pour moi est celle où vous pouvez voir l'état de chaque composant du système à tout moment. Avec le temps réel, tout est plus ou moins clair : vous pouvez agréger des données et les afficher sur un beau tableau de bord. La situation est plus compliquée avec ce qui s'est passé dans le passé, lorsque vous devez découvrir différents événements à un certain moment et les connecter les uns aux autres.
Le problème n'est en fait pas si anodin. Tout d'abord, vous devez agréger les journaux de systèmes complètement différents, qui n'ont souvent rien en commun. Deuxièmement, vous devez les lier à la même chronologie afin que les événements puissent être corrélés les uns aux autres. Et troisièmement, vous devez organiser efficacement le stockage et la récupération de cette énorme quantité de données. Cependant, comme c'est généralement le cas, la partie difficile a déjà été réglée avant nous. J'essaie plusieurs options différentes et je vais donc donner un mini-examen de ce avec quoi j'ai déjà travaillé.
Services en ligne
L'option la plus simple, qui a très bien fonctionné pour moi au début, consiste à utiliser un service cloud. De tels outils se développent activement, prenant en charge un nombre croissant de piles technologiques et s'adaptant aux spécificités des IaaS / PaaS individuels comme AWS et Heroku.
Splunk
Moi-même et récemment Alexey Sintsov avons écrit sur ce service dans une chronique. De manière générale, il ne s'agit pas seulement d'un agrégateur de journaux, mais d'un puissant système d'analyse avec une longue histoire. Par conséquent, la tâche de collecter les journaux et de les agréger pour un traitement et une recherche ultérieurs est une mince affaire pour lui. Il existe plus de 400 applications différentes, dont plus d'une centaine dans la gestion des opérations informatiques, qui collectent des informations à partir de vos serveurs et applications.
bûche
Ce service est déjà spécialement conçu pour l'analyse des journaux et vous permet d'agréger tout type de journaux de texte. Ruby, Java, Python, C / C ++, JavaScript, PHP, Apache, Tomcat, MySQL, syslog-ng, rsyslog, nxlog, Snare, routeurs et commutateurs - peu importe. Vous pouvez collecter jusqu'à 200 Mo par jour gratuitement (ce qui est beaucoup), et le forfait payant le plus proche commence à 49 $. Il fonctionne très bien.
Un excellent service qui agrège les journaux d'applications, tous les journaux de texte, syslog, etc. Ce qui est intéressant : vous pouvez travailler avec des données agrégées via un navigateur, une ligne de commande ou une API. La recherche est effectuée avec des requêtes simples telles que "15h00 hier" (obtenez les données de tous les systèmes à trois heures du matin pour hier). Tous les événements connexes seront regroupés. Pour n'importe quelle condition, vous pouvez créer une alerte afin de recevoir des avertissements à temps (les paramètres dans les configs ont changé). Vous pouvez utiliser S3 pour stocker les journaux. Le premier mois, ils donnent 5 Go en bonus, puis seulement 100 Mo par mois sont fournis gratuitement.
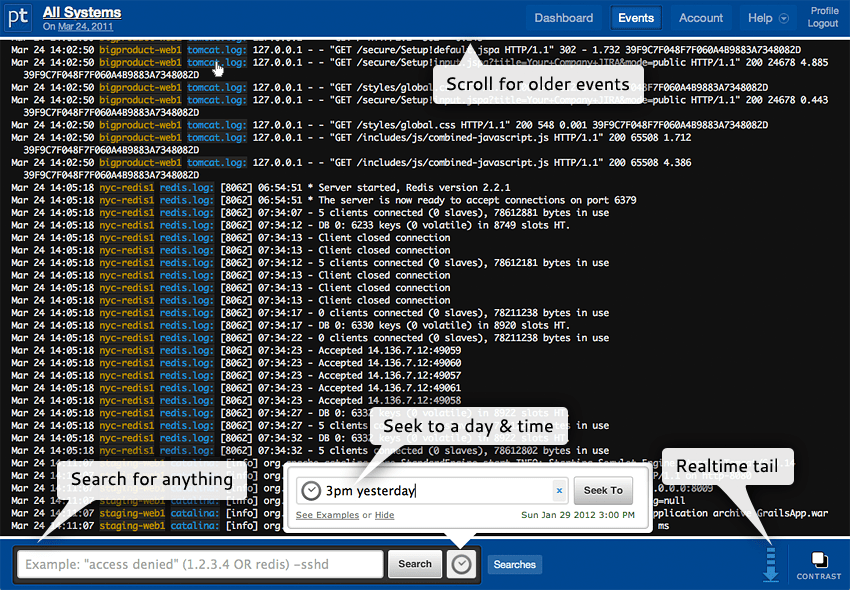
Un autre bon service de collecte de données qui vous permet de collecter gratuitement jusqu'à un gigaoctet de journaux par mois. Et les possibilités sont les mêmes : recherche puissante, queue en temps réel (tout ce qui « arrive » des logs pour le moment est affiché), stockage des données dans AWS, surveillance des PaaS, IaaS et des frameworks et langages populaires. Sur le plan gratuit, vous pouvez stocker des données pendant sept jours.

NouvelleRelique
Oui, ce service n'est pas vraiment destiné à collecter des journaux. Mais si la question porte sur la surveillance des performances des serveurs et des applications, c'est l'une des meilleures options. De plus, dans la plupart des cas, vous pouvez l'utiliser gratuitement, ce que nous avons longtemps utilisé à la rédaction pour surveiller les applications et l'état des serveurs.
Développez tout à la maison
Mes expériences avec les services en ligne se sont terminées lorsqu'il y avait tellement de données que je devais payer des montants à trois chiffres pour les agréger. Cependant, il s'est avéré que vous pouvez déployer vous-même une telle solution. Il existe deux options principales.
logstash
Il s'agit d'un système ouvert de collecte d'événements et de journaux qui a bien fonctionné dans la communauté. Le déployer, bien sûr, n'est pas difficile - mais ce n'est plus un service prêt à l'emploi prêt à l'emploi. Par conséquent, soyez prêt pour les bogues dans une mauvaise documentation, les problèmes de module et autres. Mais logstash s'acquitte de sa tâche : les journaux sont collectés et la recherche est effectuée via l'interface Web.
Courant
Si je choisis une solution autonome, alors j'aimais plus Fluentd. Contrairement à logstash, qui est écrit en JRuby et nécessite donc une JVM (ce que je n'aime pas), il est implémenté dans CRuby et les sections critiques pour les performances sont écrites en C. Le système est à nouveau open source et vous permet de collecter de gros flux de journaux utilisant plus de 1500 plugins différents. Il est bien documenté et très facile à comprendre. J'ai déployé la version actuelle du collecteur de journaux sur Fluentd.
Montrez cet article à vos amis.
Je n'ai rien vu d'inhabituel.
15 février 17:47:23 log-n1 miam : Installé : syslog-ng-3.5.6-3.el7.x86_64
15 février 17:47:36 log-n1 systemd : rechargement.
15 février 17:47:40 log-n1 syslog-ng : démarrage de syslog-ng ; version = '3.5.6 ′
15 février 17:47:40 log-n1 systemd : écoute sur Syslog Socket.
15 février 17:47:40 log-n1 systemd: Démarrage du socket Syslog.
15 février 17:47:40 log-n1 systemd: Démarrage du démon de l'enregistreur système ...
15 février 17:47:40 log-n1 systemd: Démarrage du démon de l'enregistreur système.
15 février 17:52:41 log-n1 syslog-ng : arrêt de syslog-ng ; version = '3.5.6 ′
15 février 17:52:41 log-n1 systemd: Arrêt du démon de l'enregistreur système ...
15 février 17:52:41 log-n1 systemd: délai d'attente syslog-ng.service terminé, redémarrage de la planification.
15 février 17:52:41 log-n1 systemd: Démarrage du démon de l'enregistreur système ...
15 février 17:52:41 log-n1 systemd: syslog-ng.service: processus principal terminé, code = terminé, statut = 2 / INVALIDARGUMENT
15 février 17:52:41 log-n1 systemd : Échec du démarrage du démon de l'enregistreur système.
15 février 17:52:41 log-n1 systemd: L'unité syslog-ng.service est entrée dans un état d'échec.
15 février 17:52:41 log-n1 systemd: syslog-ng.service a échoué.
15 février 17:52:42 log-n1 systemd: délai d'attente syslog-ng.service terminé, redémarrage de la planification.
15 février 17:52:42 log-n1 systemd: Démarrage du démon de l'enregistreur système ...
15 février 17:52:42 log-n1 systemd: syslog-ng.service: processus principal terminé, code = terminé, statut = 2 / INVALIDARGUMENT
15 février 17:52:42 log-n1 systemd : Échec du démarrage du démon de l'enregistreur système.
15 février 17:52:42 log-n1 systemd: L'unité syslog-ng.service est entrée dans un état d'échec.
15 février 17:52:42 log-n1 systemd: syslog-ng.service a échoué.
15 février 17:52:42 log-n1 systemd: délai d'attente syslog-ng.service terminé, redémarrage de la planification.
15 février 17:52:42 log-n1 systemd: Démarrage du démon de l'enregistreur système ...
15 février 17:52:42 log-n1 systemd: syslog-ng.service: processus principal terminé, code = terminé, statut = 2 / INVALIDARGUMENT
15 février 17:52:42 log-n1 systemd : Échec du démarrage du démon de l'enregistreur système.
15 février 17:52:42 log-n1 systemd: L'unité syslog-ng.service est entrée dans un état d'échec.
15 février 17:52:42 log-n1 systemd: syslog-ng.service a échoué.
15 février 17:52:42 log-n1 systemd: délai d'attente syslog-ng.service terminé, redémarrage de la planification.
15 février 17:52:42 log-n1 systemd : Échec du démarrage du démon de l'enregistreur système.
15 février 17:52:42 log-n1 systemd: L'unité syslog-ng.service est entrée dans un état d'échec.
15 février 17:52:42 log-n1 systemd: syslog-ng.service a échoué.
15 février 17:52:42 log-n1 systemd: demande de démarrage répétée trop rapidement pour syslog-ng.service
15 février 17:52:42 log-n1 systemd : Échec du démarrage du démon de l'enregistreur système.
15 février 17:52:42 log-n1 systemd: L'unité syslog.socket est entrée en état d'échec.
15 février 17:52:42 log-n1 systemd: syslog-ng.service a échoué.
15 février 17:53:11 log-n1 systemd : écoute sur Syslog Socket.