James Loy, Georgia Tech. Un guide du débutant, après quoi vous pouvez créer votre propre réseau de neurones en Python.
Motivation:sur la base de mon expérience personnelle dans l'apprentissage de l'apprentissage profond, j'ai décidé de créer un réseau neuronal à partir de zéro sans bibliothèque d'apprentissage complexe telle que. Je crois que comprendre la structure interne d'un réseau de neurones est important pour un Data Scientist débutant.
Cet article contient ce que j'ai appris et j'espère qu'il vous sera également utile! Autres articles connexes utiles:
Qu'est-ce qu'un réseau neuronal?
La plupart des articles sur les réseaux de neurones établissent des parallèles avec le cerveau lorsqu'ils les décrivent. Il est plus facile pour moi de décrire les réseaux de neurones comme une fonction mathématique qui mappe une entrée donnée à une sortie souhaitée sans entrer dans les détails.
Les réseaux de neurones sont composés des composants suivants:
- couche d'entrée, x
- montant arbitraire calques cachés
- couche de sortie, ŷ
- ensemble balance et déplacements entre chaque couche W et b
- choix fonctions d'activation pour chaque couche cachée σ ; dans ce travail, nous utiliserons la fonction d'activation sigmoïde
Le diagramme ci-dessous montre l'architecture d'un réseau neuronal à deux couches (notez que la couche d'entrée est généralement exclue lors du comptage du nombre de couches dans le réseau neuronal).
Créer une classe Neural Network en Python semble simple:
Formation sur les réseaux neuronaux
Production ŷ un simple réseau de neurones à deux couches:
Dans l'équation ci-dessus, les poids W et les biais b sont les seules variables qui affectent la sortie ŷ.
Naturellement, les valeurs correctes des poids et des biais déterminent la précision des prédictions. Le processus de réglage fin des poids et des biais à partir des données d'entrée est connu sous le nom de formation de réseau neuronal.
Chaque itération du processus de formation comprend les étapes suivantes
- calcul de la sortie prédite ŷ appelée propagation directe
- mise à jour des poids et biais appelés rétropropagation
Le graphique séquentiel ci-dessous illustre le processus:
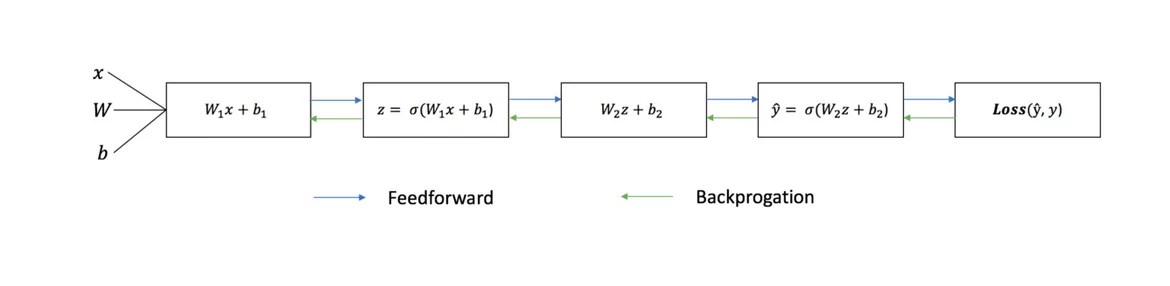
Distribution directe
Comme nous l'avons vu dans le graphique ci-dessus, la propagation directe n'est qu'un calcul facile, et pour un réseau neuronal de base à 2 couches, la sortie du réseau neuronal est donnée par:
Ajoutons une fonction feedforward à notre code Python pour ce faire. Notez que pour simplifier, nous avons supposé que les décalages sont de 0.
Cependant, nous avons besoin d'un moyen d'évaluer la «qualité» de nos prévisions, c'est-à-dire dans quelle mesure nos prévisions sont). Fonction de perte nous permet simplement de le faire.
Fonction de perte
De nombreuses fonctions de perte sont disponibles, et la nature de notre problème devrait dicter notre choix de fonction de perte. Dans ce travail, nous utiliserons somme des carrés des erreurs comme une fonction de perte.

La somme des erreurs au carré est la moyenne de la différence entre chaque valeur prédite et la valeur réelle.
Le but de la formation est de trouver un ensemble de poids et de biais qui minimise la fonction de perte.
Propagation arrière
Maintenant que nous avons mesuré notre erreur de prévision (perte), nous devons trouver un moyen propager l'erreur et mettre à jour nos pondérations et nos biais.
Pour trouver la quantité appropriée à corriger pour les pondérations et les biais, nous devons connaître la dérivée de la fonction de perte par rapport aux pondérations et aux biais.
Rappelez-vous de l'analyse que la dérivée de la fonction est la pente de la fonction.

Si nous avons une dérivée, nous pouvons simplement mettre à jour les poids et les biais en les augmentant / en les diminuant (voir le diagramme ci-dessus). On l'appelle descente graduelle.
Cependant, nous ne pouvons pas calculer directement la dérivée de la fonction de perte par rapport aux poids et biais, puisque l'équation de la fonction de perte ne contient pas de poids et de biais. Par conséquent, nous avons besoin d'une règle de chaîne pour nous aider à calculer.
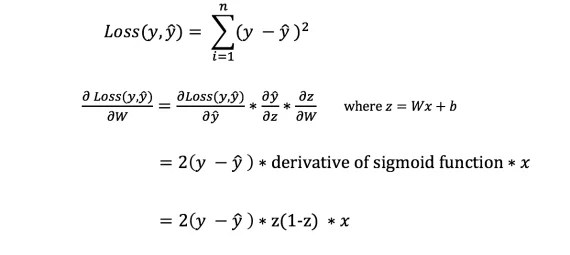
Fuh! C'était encombrant, mais cela nous permettait d'obtenir ce dont nous avions besoin - la dérivée (pente) de la fonction de perte par rapport aux poids. Nous pouvons maintenant ajuster les poids en conséquence.
Ajoutons la fonction de rétropropagation à notre code Python:
Vérification du fonctionnement du réseau neuronal
Maintenant que nous avons notre code Python complet pour effectuer une propagation avant et arrière, jetons un coup d'œil à notre réseau de neurones par exemple et voyons comment cela fonctionne.
 L'ensemble parfait de poids
L'ensemble parfait de poids Notre réseau de neurones a besoin d'apprendre l'ensemble idéal de poids pour représenter cette fonction.
Entraînons un réseau de neurones pour 1500 itérations et voyons ce qui se passe. En regardant le graphique de perte d'itération ci-dessous, nous pouvons clairement voir que la perte diminue de manière monotone jusqu'à un minimum. Ceci est cohérent avec l'algorithme de descente de gradient dont nous avons parlé plus tôt.

Regardons la prédiction finale (sortie) du réseau neuronal après 1500 itérations.

Nous l'avons fait!Notre algorithme de propagation avant et arrière a montré que le réseau de neurones fonctionnait avec succès, et les prédictions convergent vers de vraies valeurs.
Notez qu'il y a peu de différence entre les prédictions et les valeurs réelles. Ceci est souhaitable car cela évite le surajustement et permet au réseau neuronal de mieux généraliser les données invisibles.
Réflexions finales
J'ai beaucoup appris en écrivant mon propre réseau de neurones à partir de zéro. Alors que les bibliothèques d'apprentissage en profondeur telles que TensorFlow et Keras permettent de créer des réseaux profonds sans comprendre pleinement le fonctionnement interne d'un réseau de neurones, je trouve utile pour les aspirants scientifiques des données d'en acquérir une compréhension plus approfondie.
J'ai investi beaucoup de mon temps personnel dans ce travail et j'espère qu'il vous sera utile!
Cette semaine, vous pouvez lire un cas extrêmement motivant d'un étudiant de GeekBrains qui a étudié la profession, où il a parlé de l'un de ses objectifs, qui a conduit à la profession - le désir d'apprendre le principe du travail et d'apprendre à créer vous-même des robots de jeu.
En effet, c'est le désir de créer une intelligence artificielle parfaite, qu'il s'agisse d'un modèle de jeu ou d'un programme mobile, qui a poussé nombre d'entre nous sur la voie d'un programmeur. Le problème est que derrière des tonnes de matériel pédagogique et la dure réalité des clients, ce désir même a été remplacé par un simple désir de développement personnel. Pour ceux qui n'ont pas encore commencé à réaliser leurs rêves d'enfance, voici un petit guide pour créer une véritable intelligence artificielle.
Étape 1. Déception
Lorsque nous parlons de créer au moins de simples robots, les yeux sont remplis d'étincelles et des centaines d'idées clignotent dans sa tête sur ce qu'il devrait être capable de faire. Cependant, en ce qui concerne la mise en œuvre, il s'avère que les mathématiques sont la clé pour démêler le comportement réel. Oui, l'intelligence artificielle est beaucoup plus difficile que l'écriture de programmes d'application - la seule connaissance de la conception de logiciels ne vous suffira pas.
Les mathématiques sont le tremplin scientifique sur lequel votre programmation future sera construite. Sans la connaissance et la compréhension de cette théorie, toutes les idées se briseront rapidement sur l'interaction avec une personne, car un esprit artificiel n'est en réalité rien de plus qu'un ensemble de formules.
Étape 2. Acceptation
Lorsque l'arrogance est un peu renversée par la littérature étudiante, vous pouvez commencer à pratiquer. Cela ne vaut pas la peine de se précipiter vers LISP ou d'autres encore - vous devez d'abord vous familiariser avec les principes de la conception de l'IA. Python est parfait pour un apprentissage rapide et pour un développement ultérieur - c'est le langage le plus souvent utilisé à des fins scientifiques, car vous trouverez de nombreuses bibliothèques qui faciliteront votre travail.
Étape 3. Développement
Nous passons maintenant directement à la théorie de l'IA. Ils peuvent être grossièrement divisés en 3 catégories:
- Une IA faible - des robots que nous voyons dans les jeux informatiques ou de simples aides comme Siri. Ils exécutent des tâches hautement spécialisées ou constituent un complexe insignifiant, et toute imprévisibilité de l'interaction les déconcerte.
- Les IA fortes sont des machines dont l'intelligence est comparable à celle du cerveau humain. Aujourd'hui, il n'y a pas de vrais représentants de cette classe, mais des ordinateurs comme le Watson sont très proches d'atteindre cet objectif.
- L'IA parfaite est l'avenir, un cerveau de machine qui surpassera nos capacités. C'est sur les dangers de tels développements que Stephen Hawking, Elon Musk et la franchise cinématographique Terminator mettent en garde.
Naturellement, vous devriez commencer par les bots les plus simples. Pour ce faire, souvenez-vous du bon vieux jeu de tic-tac-toe lorsque vous utilisez le champ 3x3 et essayez de comprendre les algorithmes de base par vous-même: la probabilité de gagner avec des actions sans erreur, les endroits les plus réussis sur le terrain pour une pièce, la nécessité de réduire le jeu à un match nul, etc.
Plusieurs dizaines de jeux et en analysant vos propres actions, vous pourrez probablement mettre en évidence tous les aspects importants et les réécrire en code machine. Sinon, continuez à réfléchir, et ce lien est là au cas où.
À propos, si vous avez toujours utilisé le langage Python, vous pouvez créer un bot assez simple en vous référant à ce manuel détaillé. Pour les autres langages, tels que C ++ ou Java, vous n'aurez aucun mal à trouver des matériaux pas à pas non plus. Sentant qu'il n'y a rien de surnaturel derrière la création de l'IA, vous pouvez fermer le navigateur en toute sécurité et démarrer des expériences personnelles.
Étape 4. Excitation
Maintenant que les choses ont commencé, vous voulez probablement créer quelque chose de plus sérieux. Un certain nombre des ressources suivantes vous aideront à cela:
Comme vous le comprenez même d'après les noms, ce sont des API qui vous permettront de créer un semblant d'IA sérieuse sans perdre de temps.
Étape 5. Travail
Maintenant, lorsque vous comprenez déjà assez clairement comment créer une IA et quoi utiliser en même temps, il est temps de porter vos connaissances à un nouveau niveau. Tout d'abord, il nécessite une étude de discipline appelée Machine Learning. Deuxièmement, vous devez apprendre à travailler avec les bibliothèques appropriées du langage de programmation sélectionné. Pour le Python que nous envisageons, il s'agit de Scikit-learn, NLTK, SciPy, PyBrain et Numpy. Troisièmement, le développement est indispensable. Et surtout, vous pourrez désormais lire la littérature sur l'IA avec une compréhension complète du sujet:
- Intelligence artificielle pour les jeux, Ian Millington;
- Modèles de programmation de jeu, Robert Nystorm;
- Algorithmes d'IA, structures de données et expressions idiomatiques dans Prolog, Lisp et Java, George Luger, William Stbalfield;
- Neuroscience cognitive computationnelle, Randall O'Reilly, Yuko Munakata;
- Intelligence artificielle: une approche moderne, Stuart Russell, Peter Norvig.
Et oui, tout ou presque toute la littérature sur ce sujet est présentée dans une langue étrangère, donc si vous voulez créer de l'IA de manière professionnelle, vous devez améliorer votre anglais à un niveau technique. Cependant, cela est pertinent pour n'importe quel domaine de la programmation, n'est-ce pas?
Nous vivons actuellement un véritable boom des réseaux de neurones. Ils sont utilisés pour la reconnaissance, la localisation et le traitement d'images. Les réseaux de neurones sont déjà capables de faire beaucoup de choses qui ne sont pas accessibles aux humains. Nous devons aussi nous enfoncer dans cette affaire! Considérez un réseau de neutrons qui reconnaîtra les nombres dans l'image d'entrée. C'est très simple: une seule couche et une fonction d'activation. Cela ne nous permettra pas de reconnaître absolument toutes les images de test, mais nous ferons face à la grande majorité. En tant que données, nous utiliserons la collection de données MNIST connue dans le monde de la reconnaissance des nombres.
Il existe une bibliothèque python-mnist pour l'utiliser en Python. À installer:
Pip installer python-mnist
Maintenant, nous pouvons charger des données
À partir de la mnist import MNIST mndata \u003d MNIST ("/ path_to_mnist_data_folder /") tr_images, tr_labels \u003d mndata.load_training () test_images, test_labels \u003d mndata.load_testing ()
Vous devez télécharger vous-même les archives avec les données et le programme doit spécifier le chemin d'accès au répertoire avec elles. Les variables tr_images et test_images contiennent désormais des images pour la formation et le test du réseau, respectivement. Et les variables tr_labels et test_labels sont des étiquettes avec la classification correcte (c'est-à-dire des nombres d'images). Toutes les images sont au format 28x28. Définissons une variable avec une taille.
Img_shape \u003d (28, 28)
Convertissons toutes les données en tableaux numpy et normalisons-les (nous les apporterons à la taille de -1 à 1). Cela augmentera la précision des calculs.
Importez numpy en tant que np pour i dans la plage (0, len (test_images)): test_images [i] \u003d np.array (test_images [i]) / 255 pour i dans la plage (0, len (tr_images)): tr_images [i] \u003d np.array (tr_images [i]) / 255
Je note que bien qu'il soit habituel de représenter les images sous forme de tableau à deux dimensions, nous utiliserons un tableau à une dimension, c'est plus facile pour les calculs. Vous devez maintenant comprendre "qu'est-ce qu'un réseau de neurones"! Et ce n'est qu'une équation avec beaucoup de coefficients. À l'entrée, nous avons un tableau de 28 * 28 \u003d 784 éléments et 784 poids supplémentaires pour déterminer chaque chiffre. Pendant le fonctionnement du réseau neuronal, vous devez multiplier les valeurs des entrées par les poids. Additionnez les données reçues et ajoutez un décalage. Soumettez le résultat à la fonction d'activation. Dans notre cas, ce sera Relu. Cette fonction est zéro pour tous les arguments négatifs et l'argument pour tous les arguments positifs.

Il existe de nombreuses autres fonctions d'activation! Mais c'est le réseau de neurones le plus simple! Définissons cette fonction en utilisant numpy
Def relu (x): renvoie np.maximum (x, 0)
Maintenant, pour calculer l'image dans l'image, vous devez calculer le résultat pour 10 ensembles de coefficients.
Def nn_calculate (img): resp \u003d list (range (0, 10)) for i in range (0,10): r \u003d w [:, i] * img r \u003d relu (np.sum (r) + b [ i]) resp [i] \u003d r renvoie np.argmax (resp)
Pour chaque ensemble, nous obtiendrons une sortie. La sortie avec le score le plus élevé est probablement notre nombre.

Dans ce cas, 7. C'est tout! Mais non ... Après tout, vous devez prendre ces mêmes coefficients quelque part. Nous devons former notre réseau neuronal. Pour cela, la méthode de rétropropagation est utilisée. Son essence est de calculer les sorties du réseau, de les comparer avec les bonnes, puis de soustraire des coefficients les nombres nécessaires pour que le résultat soit correct. Il faut se rappeler que pour calculer ces valeurs, la dérivée de la fonction d'activation est nécessaire. Dans notre cas, c'est zéro pour tous les nombres négatifs et 1 pour tous les positifs. Déterminons les coefficients de manière aléatoire.
W \u003d (2 * np.random.rand (10, 784) - 1) / 10 b \u003d (2 * np.random.rand (10) - 1) / 10 pour n dans la plage (len (tr_images)): img \u003d tr_images [n] cls \u003d tr_labels [n] # propagation avant resp \u003d np.zeros (10, dtype \u003d np.float32) pour i dans l'intervalle (0,10): r \u003d w [i] * img r \u003d relu ( np.sum (r) + b [i]) resp [i] \u003d r resp_cls \u003d np.argmax (resp) resp \u003d np.zeros (10, dtype \u003d np.float32) resp \u003d 1.0 # propagation de retour true_resp \u003d np. zéros (10, dtype \u003d np.float32) true_resp \u003d 1.0 error \u003d resp - true_resp delta \u003d error * ((resp\u003e \u003d 0) * np.ones (10)) pour i dans la plage (0,10): w [i ] - \u003d np.dot (img, delta [i]) b [i] - \u003d delta [i]
Au cours du processus d'entraînement, les coefficients deviendront légèrement similaires aux nombres:
Vérifions l'exactitude du travail:
Def nn_calculate (img): resp \u003d list (range (0, 10)) for i in range (0,10): r \u003d w [i] * img r \u003d np.maximum (np.sum (r) + b [ i], 0) #relu resp [i] \u003d r renvoie np.argmax (resp) total \u003d len (test_images) valide \u003d 0 invalide \u003d pour i dans l'intervalle (0, total): img \u003d test_images [i] prédit \u003d nn_calculate (img) vrai \u003d test_labels [i] si prédit \u003d\u003d vrai: valide \u003d valide + 1 autre: invalide.append (("image": img, "prédit": prédit, "vrai": vrai)) print ("précision () ". format (valide / total))
J'ai eu 88%. Pas si cool, mais très intéressant!
Cette fois, j'ai décidé d'étudier les réseaux de neurones. J'ai pu acquérir des compétences de base dans ce domaine au cours de l'été et de l'automne 2015. Par compétences de base, je veux dire que je peux créer moi-même un simple réseau de neurones à partir de zéro. Vous pouvez trouver des exemples dans mes référentiels sur GitHub. Dans cet article, je fournirai des éclaircissements et partagerai des ressources que vous pourriez trouver utiles à explorer.
Étape 1. Les neurones et la méthode par anticipation
Alors, qu'est-ce qu'un "réseau neuronal"? Attendons avec cela et traitons d'abord un neurone.
Un neurone est comme une fonction: il prend plusieurs valeurs en entrée et en renvoie une.
Le cercle ci-dessous représente un neurone artificiel. Il obtient 5 et renvoie 1. L'entrée est la somme des trois synapses connectées au neurone (trois flèches sur la gauche).
Sur le côté gauche de l'image, nous voyons 2 valeurs d'entrée (vert) et un décalage (surligné en marron).
Les données d'entrée peuvent être des représentations numériques de deux propriétés différentes. Par exemple, lors de la création d'un filtre anti-spam, ils peuvent signifier la présence de plus d'un mot dans les LETTRES MAJUSCULES et la présence du mot «viagra».
Les valeurs d'entrée sont multipliées par leurs soi-disant «poids», 7 et 3 (surlignés en bleu).
Maintenant, nous ajoutons les valeurs résultantes avec le décalage et obtenons un nombre, dans notre cas 5 (surligné en rouge) C'est l'entrée de notre neurone artificiel.

Ensuite, le neurone effectue une sorte de calcul et génère une valeur de sortie. Nous en avons 1 parce que la valeur sigmoïde arrondie au point 5 est 1 (nous parlerons plus en détail de cette fonction plus tard).
S'il s'agissait d'un filtre anti-spam, le fait de la sortie 1 signifierait que le texte a été marqué comme spam par le neurone.

Illustration du réseau neuronal de Wikipedia.
Si vous combinez ces neurones, vous obtenez un réseau de neurones simple - le processus va de l'entrée à la sortie, via des neurones connectés par des synapses, comme dans l'image de gauche.
Étape 2. Sigmoïde
Après avoir regardé les didacticiels Welch Labs, c'est une bonne idée de consulter la quatrième semaine du cours d'apprentissage automatique de Coursera sur les réseaux de neurones pour vous aider à comprendre comment ils fonctionnent. Le cours est très approfondi en mathématiques et est basé sur Octave, et je préfère Python. Pour cette raison, j'ai sauté les exercices et j'ai appris toutes les connaissances nécessaires à partir de la vidéo.

Le sigmoïde mappe simplement votre valeur (le long de l'axe horizontal) sur une plage de 0 à 1.
La première priorité pour moi était d'étudier le sigmoïde, tel qu'il figurait dans de nombreux aspects des réseaux de neurones. Je savais déjà quelque chose sur elle depuis la troisième semaine du cours ci-dessus, alors j'ai revu la vidéo à partir de là.
Mais les vidéos seules ne vous mèneront pas très loin. Pour une compréhension complète, j'ai décidé de le coder moi-même. J'ai donc commencé à écrire une implémentation d'un algorithme de régression logistique (qui utilise un sigmoïde).
Cela a pris une journée entière et le résultat n'était guère satisfaisant. Mais ce n'est pas grave, car j'ai compris comment tout fonctionne. Vous pouvez voir le code.
Vous n'êtes pas obligé de le faire vous-même, car cela nécessite des connaissances particulières - l'essentiel est que vous compreniez le fonctionnement du sigmoïde.
Étape 3. Méthode de rétropropagation
Comprendre le fonctionnement d'un réseau neuronal de l'entrée à la sortie n'est pas si difficile. Il est beaucoup plus difficile de comprendre comment un réseau de neurones est formé sur des ensembles de données. Le principe que j'ai utilisé s'appelle